.svg)
The Voxco Answers Anything Blog
Read on for more in-depth content on the topics that matter and shape the world of research.




Inspire. Learn. Create.
Text Analytics & AI
AI & Open End Analysis
How to Choose the Right Solution
The Latest in Market Research
Market Research 101


Text Analytics & AI
Text Mining Software and Text Analysis Tools
What is Text Mining
Businesses collect many types of text data, but it’s difficult to get value out of this information when manual handling is required to process it. It’s impossible to perform these duties at a scale that many companies require when you rely on manual processing, but text mining technology provides the automation needed to accomplish this goal.At its most basic level, text mining is an automated method of extracting information from written data. There are three major categories that text mining can fall under:Information extraction: The text analysis software can identify and pull information directly from the text, which is often presented in a natural language form. The software can find data that is the most important by structuring the written input and identifying any patterns that show up in the data set.Text analysis: This type of text mining analyzes the written input for various trends and patterns and prepares the data for reporting purposes. It relies heavily on natural language processing to work with this information, as well as other types of automated analysis. The business receives actionable insights into their unstructured data.Knowledge discovery and extraction: Data contained in unstructured sources is processed with machine learning and allows companies to quickly track down relevant and useful information contained in a variety of resources.Learn more about how text mining impacts business.
How is Text Mining Used
One of the most common ways to use text mining in a business environment is for sentiment analysis. This use case allows customer experience teams, research professionals, human resource teams, marketers, and other professionals to understand how their audience feels about specific questions or topics. Net Promoter Scores and similar surveys significantly benefit from text mining.In sentiment analysis, the data will either be positive, negative, or neutral. The software also determines how far in a certain direction this sentiment goes. You can use this information to guide your decision-making, respond to feedback from customers or employees, and to strengthen the data that you collect from other sources.The type of text mining needed for your business depends on the data that you’re working with, the information that you’re trying to get out of your written sources, and the end use of that analysis. Text mining tools come in many shapes and forms, and the right solution depends on many factors. Here are a few options to consider.
Best Free Text Mining Tools
When you’re not sure exactly how you want to use text mining for your organization, working with a free tool makes a lot of sense. You can experiment with a variety of options to see the ones that provide the best utility and will work with your current infrastructure. Here are some of the best free text mining tools on the market.
Aylien
Aylien is an API designed for analyzing text contained in Google Sheets and other text sources. You can set this up as a business intelligence tool that’s capable of performing sentiment analysis, labeling documents, suggesting hashtags, and detecting the language that a particular data set is in. One particularly useful feature is that it can use URLs as a source as well, and it’s designed to only extract the text from a web page rather than pulling in all of the content. Your organization would need a development team that can work with the API
Keatext
Keatext is an open source text mining platform that works with larger unstructured data sets. The system can do sentiment analysis without your company needing to configure a complete text mining solution, which can involve a lot of work on the backend if it’s not cloud-based. In addition to picking up on customer sentiment in the text, it also categorizes responses into broad topics: suggestions, questions, praise, and problems.
Datumbox
Datumbox is not strictly a text mining solution. Instead, it’s a Machine Learning framework in Java that has many capabilities that allow your company to leverage it for this purpose. It’s also an open source service. This platform groups its services into different applications, and here are the ones most relevant to text analysis software.
- Text Extraction
- Language Detection
- Sentiment Analysis
- Topic Classification
- Keyword Extraction
This robust framework offers a REST API to use these functions in your custom development projects. It includes many algorithms and models for working with unstructured data. It’s relatively straightforward to work with, although this is better for organizations that have custom development resources available.
KHCoder
KHCoder provides text mining capabilities that support a range of languages. Many text analysis software is limited in the language support available, which is not an ideal situation for companies that operate on a global level, or for those that are in regions where more than one language is spoken at a native level. KHCoder covers 13 major languages, ranging from Dutch to Simplified Chinese.
RapidMiner Text Mining Extension
RapidMiner Text Mining Extension is part of a comprehensive data science platform. This solution is designed for advanced users, such as data scientists and data engineers. You can extract useful information from written resources, including social media updates, research journals, reviews, and others. However, this platform may be overkill for organizations that are not trying to get into the nuts and bolts of data science. It's easy to get overwhelmed with the functionality, which results in a long implementation and training period.
Textable
Textable is an open source text mining software that focuses on visualizing the insights that you gain. For its basic text analysis functions, you can filter segments, create random text for sampling, and put expressions in place to automate segmenting text data.For more advanced text mining, you can use complex algorithms that include clustering, look at segment distribution, and leverage linguistic complexity analysis. It can also recode the text that you input into it as needed.This software is flexible and extendable, although it’s limited to smaller sets of data overall, making it better for smaller businesses than larger organizations. It’s compatible with many technologies, allowing you to use Python for additional scripting. It supports practically any text data format and encoding.Unlike many other free text mining solutions, Textable is relatively user-friendly and offers a visual interface and built-in functions that cover your typical text mining operations. It has significant support from the developer community, so if your company has questions, support is readily available. This is a relatively beginner-friendly option, with some good features for intermediate users as well.
Google Cloud Natural Language API
Google offers its own cloud-based Natural Language API for companies that are looking to leverage a robust set of functionalities offered by this tech giant. This is a machine learning platform that supports classification, extraction, and sentiment analysis.Google has pre-trained its natural language processing models in this solution, so you don’t have to go through that step before extracting your data. It’s deeply integrated with Google’s cloud storage solutions, which can be handy if you’re already using that as a key part of your infrastructure or you need an accessible location to store large volumes of text data.This text mining solution also supports audio analysis through the Speech-to-Text API and optical character recognition to quickly analyze documents scanned into the system. Another integration that can prove useful is being able to use the Google Translation API in order to get a sentiment analysis run on data sources with multiple languages.This solution is best for mid to large-sized companies that have advanced text analysis needs and the development team to support custom solutions and models. Smaller companies may not have the resources they need to get enough value out of this platform, and may not have users with enough technical knowledge to get everything set up and operational.
General Architecture for Text Engineering
General Architecture for Text Engineering, otherwise known as GATE, is a comprehensive text processing toolkit that equips development teams with the resources they need for their text mining needs.This toolkit requires a team capable of implementing it in the organization through custom development, and there is an active community surrounding it. If you want a strong toolkit for implementing text mining into your own applications, this is a good place to get started.
The Benefits of Premium Text Mining Tools
Free text mining solutions are useful for discovering what type of capabilities you need for your organization, but they often have a significant outlay for scaling it up to the level that your organization needs in a production environment. Premium text mining tools, such as the Ascribe Intelligence Suite, provide many benefits that provide a strong ROI that more than balances out the costs associated with implementing this solution. Here are several of the benefits that this premium text analysis suite brings to the table.
Code Verbatim Comments Quickly and Accurately
Ascribe Coder simplifies the process of categorizing large sets of verbatim comments. This computer assisted coding solution empowers your staff with the capabilities they need to be highly productive when working their way through survey responses, email messages, social media text, and other sources. Some ways that you can implement this in your organization is through testing advertising copy, studying your Net Promoter Score, working through employee engagement surveys, and doing a deep dive into what people are really saying in customer satisfaction surveys.
Gain Actionable Insights From Customer Feedback
Ascribe CX Inspector goes through sets of verbatim comments and provides complete analysis and visualization, allowing your organization’s decision-makers to quickly act on this information. The automated functionality cuts down the time it takes to get usable insights from your unstructured data sets. An Instant Dashboard makes it easy to look at the information with different types of visualization, and the advanced natural language processing technology is incredibly powerful. Whether you want to use this to go through employee engagement surveys or fuel your Voice of the Customer studies, you have a robust tool on hand.
Automatically Learn More About Your Customer Experience
CX Inspector offers a highly customizable solution for researchers looking for an advanced text analytics utility. Both sentiment analysis and topic classification are included in this part of the suite, discovered with the help of natural language processing and AI. You get to better understand the “Why” behind why your customers gave you a particular score, and how you can improve.It includes many advanced features including removing personally identifiable information, supporting custom rulesets, working with unstructured and structured data, creating customized applications with an API connector, and results comparison.The interface is user-friendly and includes drag-and-drop control for developing custom taxonomies.It’s especially useful for companies who have many languages used in their verbatim comments – this solution supports 100 languages with automatic translation.
Better Understand Your Text Analysis Through Powerful Visualizations
Getting a lot of insights out of your text mining is the first step to truly using them to fuel a data-driven action plan. Ascribe Illustrator allows you to take the next step by providing your organization with powerful and flexible data visualizations that help non-technical stakeholders understand the analytics produced by text mining platforms.Here are a few of the many visualizations that you can use with this premium text mining software:
- Real-time visualization
- Correlation matrix
- Dynamic visualization
- Granular report detail
- Mirror charts
- Powerful filters
- Structured data integration
- Easily import and export data from multiple sources
- User-friendly dashboards
- Enhanced Word Clouds
- Heat maps
- Co-occurrence charts
While paying for a premium text analytics software may require an upfront investment, you end up getting a significantly higher value out of a platform like Ascribe than you would with free solutions. Your verbatim feedback and other text data contain some of the most valuable data available in your organization. It makes sense to work with a premium product that allows everyone from non-technical stakeholders to data scientists to effectively use it.
4/9/20
Read more
Text Analytics & AI
Natural Language processing (NLP) for Machine and Process Learning - How They Compare
Natural language is a phrase that encompasses human communication. The way that people talk and the way words are used in everyday life are part of natural language. Processing this type of natural language is a difficult task for computers, as there are so many factors that influence the way that people interact with their environment and each other. The rules are few and far between, and can vary significantly based on the language in question, as well as the dialect, the relationship of the people talking, and the context in which they are having the conversation.Natural language processing (NLP) is a type of computational linguistics that uses machine learning to power computer-based understanding of how people communicate with each other. NLP leverages large data sets to create applications that understand the semantics, syntax, and context of a given conversation.Natural language processing is an essential part of many types of technology, including voice assistance, chat bots, and improving sentiment analysis. NLP analytics empowers computers to understand human speech in text and/or written form without needing the person to structure their conversation in a specific way. They can talk or type naturally, and the NLP system interprets what they’re asking about from there.Machine learning is a type of artificial intelligence that uses learning models to power its understanding of natural language. It’s based off of a learning framework that allows the machine to train itself on data that’s been input. It can use many types of models to process the information and develop a better understanding of it. It’s able to interpret both standard and out of the ordinary inquiries. Due to its continual improvements, it’s able to handle these edge cases without getting tripped up, unlike a strict rules-based system.Natural language processing brings many benefits to an organization that has many processes that depend on natural language input and output. The biggest advantage of NLP technology is automating time-consuming processes, such as categorizing text documents, answering basic customer support questions, and gaining deeper insight into large text data sets.
Is Natural Language Processing Machine Learning?
It’s common for some confusion to arise over the relationship between natural language processing and machine learning. Machine learning can be used as a component in natural language processing technology. However, there are many types of NLP machines that perform more basic functionality and do not rely on machine learning or artificial intelligence. For example, a natural language processing solution that is simply extracting basic information may be able to rely on algorithms that don’t need to continually learn through AI.For more complex applications of natural language processing, the systems are using machine learning models to improve their understanding of human speech. Machine learning models also make it possible to adjust to shifts in language over time. Natural language processing may be using supervised machine learning, unsupervised machine learning, both, or neither alongside other technologies to fuel its applications.Machine learning can pick up on patterns in speech, identify contextual clues, understand the sentiment behind a message, and learn other important information about the voice or text input. Sophisticated technology solutions that require a high-level of understanding to hold conversations with humans require machine learning to make this possible.
Machine Learning vs. Natural Language Processing (NLP)
You can think of machine learning and natural language processing in a Venn diagram that has many pieces in the overlapping section. Machine learning has many useful features that help with the development of natural language processing systems, and both of them fall under the broad label of artificial intelligence.Organizations don’t need to choose one or the other for development that involves natural language input or output. Instead, these two work hand-in-hand to tackle the complex problem that human communication represents.
Supervised Machine Learning for Natural Language Processing and Text Analytics
Supervised machine learning means that the system is given examples of what it is supposed to be looking for so it knows what it is supposed to be learning. In natural language processing applications and machine learning text analysis, data scientists will go through documents and tag the important parts for the machine.It is important that the data fed into the system is clean and accurate, as this type of machine learning requires quality input or it is unable to produce the expected results. After a sufficient amount of training, data that has not been tagged at all is sent through the system. At that point, the machine learning technology will look at this text and analyze it based on what it learned from the examples.This machine learning use case leverages statistical models to fuel its understanding. It becomes more accurate over time, and developers can expand the textual information it interprets as it learns. Supervised machine learning does have some challenges when it comes to understanding edge cases, as natural language processing in this context relies heavily on statistical models.While the exact method that data scientists use to train the system varies from application to application, there are a few core categories that you’ll find in natural language processing and text analytics.
- Tokenization: The text gets distilled into individual words. These “tokens” allow the system to start by identifying the base words involved in the text before it continues processing the material.
- Categorization: You teach the machine about the important, overarching categories of content. The manipulation of this data allows for a deeper understanding of the context the text appears in.
- Classification: This identifies what class the text data belongs to.
- Part of Speech tagging: Remember diagramming sentences in English class? This is essentially the same process, just for a natural language processing system.
- Sentiment analysis: What is the tone of the text? This category looks at the emotions behind the words, and generally assigns it a value that falls under positive, negative, or neutral standing.
- Named entity recognition: In addition to providing the individual words, you also need to cover important entities. For some systems, this refers to names and proper nouns. In others, you’ll need to highlight other pieces of information, such as hashtags.
Unsupervised Machine Learning for Natural Language Processing and Text Analytics
Unsupervised machine learning does not require data scientists to create tagged training data. It doesn’t require human supervision to learn about the data that is input into it. Since it’s not operating off of defined examples, it’s able to pick up on more out-of-the-box cases and patterns over time. Since it’s less labor intensive than a supervised machine learning technique, it’s frequently used to analyze large data sets and broad pattern recognition and understanding of text.There are several types of unsupervised machine learning models:
- Clustering: Text documents that are similar are clustered into sets. The system then looks at the hierarchy of this information and organizes it accordingly.
- Matrix factorization: This machine learning technique looks for latent factors in data matrices. These factors can be defined in many ways, and are based on similar characteristics.
- Latent Semantic Indexing: Latent Semantic Indexing frequently comes up in conversations about search engines and search engine optimization. It refers to the relationship between words and phrases so that it can group related text together. You can see an example of this technology in action whenever Google suggests search results that include contextually related words.
Deep Learning
Another phrase that comes up frequently in discussions about natural language processing and machine learning is deep learning. Deep learning is artificial intelligence technology based on simulating the way the human brain works through a large neural network. It’s used to expand on learning algorithms, deal with data sets that are ever-increasing in size, and to work with more complex natural language use cases.It gets its name by looking deeper into the data than standard machine learning techniques. Rather than getting a surface-level understanding of the information, it produces comprehensive and easily scalable results. Unlike machine learning, deep learning does not hit a wall in how much it can learn and scale over time. It starts off by learning simple concepts and then builds upon this learning to expand into more complicated ones. This continual building process makes it possible for the machine to develop a broad range of understanding that’s necessary for high-level natural language processing projects.Deep learning also benefits natural language processing in improving both supervised and unsupervised machine learning models. For example, it has a functionality referred to as feature learning that is excellent for extracting information from large sets of raw data.
NLP Machine Learning Techniques
Text mining and natural language processing are related technologies that help companies understand more about text that they work with on a daily basis. The importance of text mining can not be underestimated.The type of machine learning technique that a natural language processing system uses depends on the goals of the application, the resources available, and the type of text that’s being analyzed. Here are some of the most common techniques you’ll encounter.
Text Embeddings
This technique moves beyond looking at words as individual entities. It expands the natural language processing system’s understanding by looking at what surrounds the text where it’s embedded. This information provides valuable context clues about the situation in which the word is being used, whether its meaning is changed from the base dictionary definition, and what the user means when they are using it.You’ll often find this technique used in deep learning natural language processing applications, or those that are addressing more complex use cases that require a better understanding of what’s being said. When this technique looks for contextually relevant words, it also automates the removal of text that doesn’t further understanding. For example, it doesn’t need to process articles such as “a” and “an.”One representation of text embeddings technique in action is with predictive text on cell phones. It’s attempting to predict the next word in the sequence, which it’s only able to do by identifying words and phrases that appear around it frequently.
Machine Translation
This technique allows NLP systems to automate the translation process from one language to another. It relies on both word-for-word translations and those that are able to identify and get context to facilitate accurate translations between languages. Google Translate is one of the most well-known use cases of this technique, but there are many ways that it’s used throughout the global marketplace.Machine learning and deep learning can improve the results by allowing the system to build upon its base understanding over time. It might start out with a supervised machine learning model that inputs a dictionary of words and phrases to translate and then grows that understanding through multiple data sources. This evolution over time allows it to pick up on speech and language nuances, such as slang.Human language is complex and being able to produce accurate translations requires a powerful natural language processing system that can work with both the base translation and contextual cues that lead to a deeper understanding of the message that is being communicated. It’s the difference between base translation and interpretation.In a global marketplace, having a powerful machine translation solution available means that organizations can address the needs of the international markets in a way that scales seamlessly. While you still need human staff to go through the translations to correct errors and localize the information for the end user, it takes care of a substantial part of the heavy lifting.
Conversations
One of the most common contexts that natural language processing comes up in is conversational AI, such as chatbots. This technique is focused on allowing a machine to have a naturally flowing conversation with the users interacting with it. It moves away from a fully scripted experience by allowing the bot to create a more natural sounding response that fits into the flow of the conversation.Basic chatbots can provide the users with information that’s based on key parts of the input message. They can identify relevant keywords within the text, look for phrases that indicate the type of assistance the user needs, and work with other semi-structured data. The user doesn’t need to change the way they typically type to get a relevant response.However, open-ended conversations are not possible on the basic end of things. A more advanced natural language processing system leveraging deep learning is needed for advanced use cases.The training data used for understanding conversations often comes from the company’s communications between customer service and the customers. It provides broad exposure to the way people talk when interacting with the business, allowing the system to understand requests made in a wide range of conversational styles and dialects. While everyone reaching out to the company may share a common language, their verbiage, slang, and writing voice can be drastically different from person to person.
Sentiment Analysis
Knowing what is being communicated depends on more than simply understanding the words being said. It’s also important to consider the emotions behind the conversation. For example, if you use natural language processing as part of your customer support processes, it’s important to know whether the person is frustrated and experiencing negative emotions. Sentiment analysis is the technique that brings this data to natural language processing.The signs that someone is upset can be incredibly subtle in text form, and requires a lot of data about negative and positive emotions in text-based form. This technique is useful when you want to learn more about your customer base and how they feel about your company or products. You can use sentiment analysis tools to automate the process for going through customer feedback from surveys to get a big picture view of their feelings.This type of system can also help you sort responses into those that may need a direct response or follow-up, such as those that are overwhelmingly negative. It’s an opportunity for a business to right wrongs and turn detractors into advocates. On the flip side, you can also use this information to determine people who would be exceptional customer advocates, as well as those who could use a little push to end up on the positive side of the sentiment analysis.The natural language processing system uses an understanding of smaller elements of the text to get to the meaning behind the text. It automates a process that can be incredibly painstaking to try to do manually.
Question Answering
Natural language processing is really good at automating the process of answering questions and finding relevant information by analyzing text from multiple sources. It creates a quality user experience by digging through the data to find the exact answer to what they’re asking, without requiring them to sort through multiple documents on their own or find the answer buried in the text.The key functions that NLP must be able to perform in order to answer questions include: understanding the question being asked, the context it’s being asked in, and the information that best addresses the inquiry. You’ll frequently see this technique used as part of customer service, information management, and chatbot products.Deep learning is useful for this application, as it can distill the information into a contextually relevant answer based on a wide range of data. It determines whether the text is useful for answering the inquiry, and the parts that are most important in this process.Once it goes through this sequence, it then needs to be assembled in natural language so the user can understand the information.
Text Summarization
Data sets have reached awe-inspiring sizes in the modern business world, to the point where it would be nearly impossible for human staff to manually go through the different information to create summaries of the data. Thankfully, natural language processing is capable of automating this process to allow organizations to derive value from these big data sets.There are a few aspects that text summarization needs to address with the use of natural language processing. The first is that it needs to understand and recognize the parts of the text that are the most important to the users accessing it. The type of information that is most-needed from a document would be drastically different for a doctor and an accountant.The information must be accurate and presented in a form that is short and easy to understand. Some real-world examples of this technique in use include automated summaries of news stories, article digests that provide a useful excerpt as a preview, and the information that is given in alerts in a system.The way this technique works is by scanning the document for different word frequencies. Words that appear frequently are likely to be important to understanding the full text. The sentences that contain these words are pulled out as the ones that are most likely to produce a basic understanding of the document, and it then sorts these excerpts in a way that matches the flow of the original.Text summarization can go a step further and move from an intelligent excerpt to an abstract that sounds natural. The latter requires more advanced natural language processing solutions that can create the summary and then develop the abstract in natural dialogue.
Attention Mechanism
Attention in the natural language processing context refers to the way visual attention works for people. When you look at a document, you are paying attention to different sections of the page rather than narrowing your focus to an individual word. You might skim over the text for a quick look at this information, and visual elements such as headings, ordered lists, and important phrases and keywords will jump out to you as the most important data.The Attention mechanism techniques build on the way people look through different documents. It operates on a hierarchy of the most important parts of the text while placing lesser focus on anything that falls outside of that primary focus. It’s an excellent way of adding relevancy and context to natural language processing. You’ll find this technique used in machine translation and creating automated captions for images.Are you ready to see what natural language processing can do for your business? Contact us to learn more about our powerful sentiment analysis solutions that provide actionable, real-time information based on user feedback.
3/9/20
Read more
Text Analytics & AI
Customer Experience Analysis - How to improve customer loyalty and retention
The global marketplace puts businesses in a position where you need to compete with organizations from around the world. Standing out on price becomes a difficult or impossible task, so the customer experience has moved into a vital position of importance. Customer loyalty and retention are tied to the way your buyers feel about your brand throughout their interactions. Customer experience analysis tools provide vital insight into the ways that you can address problems and lead consumers to higher satisfaction levels. However, knowing which type of tool to use and the ways to collect the data for them are important to getting actionable information.
Problems With Only Relying on Surveys for Customer Satisfaction Metrics
One of the most common ways of collecting data about the customer experience is through surveys. You may be familiar with the Net Promoter Score system, which rates customer satisfaction on a 1-10 scale. The survey used for this method is based off a single question — “How likely are you to recommend our business to others?” Other surveys have a broad scope, but both types focus on closed-ended questions. If the consumer had additional feedback on topic areas that aren't covered in the questions, you lose the opportunity to collect that data. Using open-ended questions and taking an in-depth look at what customers say in their answers gives you a deeper understanding of your positive and negative areas. Sometimes this can be as simple as putting a text comment box at the end. In other cases, you could have fill-in responses for each question.
How to Get Better Customer Feedback
To get the most out of your customer experience analysis tools, you need to start by establishing a plan to get quality feedback. Here are three categories to consider:
Direct
This input is given to your company by the customer. First-party data gives you an excellent look at what the consumers are feeling when they engage with your brand. You get this data from a number of collection methods, including survey results, studies and customer support histories.
Indirect
The customer is talking about your company, but they aren't saying it directly to you. You run into this type of feedback on social media, with buyers sharing information in groups or on their social media profiles. If you use social listening tools for sales prospecting or marketing opportunities, you can repurpose those solutions to find more feedback sources. Reviews on people's websites, social media profiles, and dedicated review websites are also important.
Inferred
You can make an educated guess about customer experiences through the data that you have available. Analytics tools can give you insight on what your customers do when they're engaging with your brand. Once you're collecting customer data from a variety of sources, you need a way to analyze it properly. A sentiment analysis tool looks through the customer information to tell you more about how they feel about the experience and your brand. While you can try to do this part of the process manually, it requires an extensive amount of human resources to accomplish, as well as a lot of time.
Looking at Product-specific Customer Experience Analytics
One way to use this information to benefit customer loyalty and satisfaction is by analyzing it on a product-specific basis. When your company has many offerings for your customers, looking at the overall feedback makes it difficult to know how the individual product experiences are doing. A sentiment analysis tool that can sort the feedback into groups for each product makes it possible to look at the positive and negative factors influencing the customer experience and judge how to improve sentiment analysis. Some of the information that you end up learning is whether customers want to see new features or models with your products, if they've responded to promotions during the purchase process, and if products may need shelves or need to be completely reworked.
Improving the Customer Experience for Greater Loyalty
If you find that your company isn't getting a lot of highly engaged customer advocates, then you may be running into problems generating loyalty. To get people to care more about your business, you need to fully understand your typical customers. Buyer personas are an excellent tool to keep on hand for this purpose. Use data from highly loyal customers to create profiles that reflect those characteristics. Spend some time discovering the motivations and needs that drive them during the purchase decision. When you fully put yourself in the customer's shoes, you can begin to identify ways to make them more emotionally engaged in their brand support. One way that many companies drive more loyalty is by personalizing customer experiences. You give them content, recommendations and other resources that are tailored to their lifestyle and needs.
Addressing Weak Spots in Customer Retention
Many factors lead to poor customer retention. Buyers may feel like the products were misrepresented during marketing or sales, they could have a hard time getting through to customer support, or they aren't getting the value that they expected. In some cases, you have a product mismatch, where the buyer's use case doesn't match what the item can accomplish. A poor fit leads to a bad experience. Properly educating buyers on what they're getting and how to use it can lead to people who are willing to make another purchase from your company. You don't want to center your sales tactics on one-time purchases. Think of that first purchase as the beginning of a long-term relationship. You want to be helpful and support the customer so they succeed with your product lines. Sometimes that means directing them to a competitor if you can't meet their needs. This strategy might sound counterintuitive, but the customers remember that you went out of your way to help them, all the way up to sending them to another brand. They'll happily mention this good experience to their peers. If their needs change in the future, you could end up getting them back. Customer loyalty and retention are the keys to a growing business. Make sure that you're getting all the information you need out of your feedback to find strategies to build these numbers up.
2/10/20
Read more
Text Analytics & AI
Machine Learning for Text Analysis
“Beware the Jabberwock, my son!
The jaws that bite, the claws that catch!
Beware the Jubjub bird, and shun
The frumious Bandersnatch!”
— Lewis Carroll
Verbatim coding seems a natural application for machine learning. After all, for important large projects and trackers we often have lots of properly coded verbatims. These seem perfect for machine learning. Just tell the computer to learn from these examples, and voilà! We have a machine learning model that can code new responses and mimic the human coding. Sadly, it is not that simple.
Machine Learning Basics
To understand why, you need to know just a bit about how machine learning works. When we give the computer a bunch of coded verbatims and ask it to learn how to code them we are doing supervised machine learning. In other words, we are not just asking the computer to “figure it out”. We are showing it how proper coding is done for our codeframe and telling it to learn how to code similarly. The result of the machine learning process is a model containing the rules based on what the computer has learned. Using the model, the computer can try to code new verbatims in a manner that mimics the examples from which it has learned.
There are many supervised machine learning tools with different topics, information, algorithms, and features out there. Amazon Web Services offers several, which you can read about here if you have interest. There are even machine learning engines developed specifically for coding survey responses. One of these was offered by Ascribe for several years. The problem with these tools is that the machine learning model is opaque. You can’t look inside the model to understand why it makes its decisions.
Problems with Opaque Machine Learning Models
So why are opaque models bad? Let’s suppose you train up a nice machine learning model for a tracker study you have fielded for several waves. In comes the next wave, and you code it automatically with the model. It won’t get it perfect of course. You will have some verbatims where a code was applied when it should not have been. This is a False Positive, or an error of commission. You will also find verbatims where a code was not applied that should have been. This is a False Negative, or error of omission. How do we now correct the model so that it does not make these mistakes again?
Correcting False Negatives
Correcting false negatives is not too difficult, at least in theory. You just come up with more examples of where the code is correctly applied to a verbatim. You put these new examples in the training set, build the model again, and hopefully the number of these false negatives decreases. Hopefully. If not, you lather, rinse, and repeat.
Correcting False Positives
Correcting false positives can get maddening. For this you need more examples where the code was correctly not applied to a verbatim. But what examples? And how many? In practice the number of examples to correct false positives can be far larger than to correct false negatives.
The Frumious Downward Accuracy Spiral
One of the promises of machine learning is that over time you have more and more training examples, so you can retrain the model with these new examples and the model will continue to improve, right? Wrong. If you retrain with new examples provided by using your machine learning model the accuracy will go down, not up. Text mining and natural language processing are related technologies that help companies understand more about text analytics that they work with on a daily basis. Using examples containing mistakes from the natural language machine learning model reinforces those mistakes. You can avoid this by thoroughly checking the different verbatims coded within the machine learning tool and using these corrected examples to retrain the model. But who is going to do that? This error checking takes a good fraction of the time that would be required to simply manually code the verbatims. The whole point of using natural language machine learning is not to spend this time and to make the best use of your time through the help and use of NLP. So, either the model gets worse over time, or you spend nearly as much labor and work on your training set as if you were not using the machine learning tool.
Learn more about how text mining can impact businesses.
Explainable Machine Learning Models
It would be great if you could ask the machine learning model why it made the decision that led to a coding error. If you knew that, at least you would be in a better position to conjure up new training examples within machine learning text analysis to try to fix the problems. It would be even better if you could simply correct that decision logic in the model without needing to retrain the model or find new training examples.
This has led different companies like IBM to research Explainable AI tools. The IBM AI Explainability 360 project is an example of this work, but other researchers are also pursuing this concept.
At Ascribe we are developing a machine learning tool that is both explainable and correctable. In other words, you can look inside the machine learning model to best understand why it makes its decisions, and you can correct these decisions as well if needed.
Structure of an Explainable Machine Learning Model for Verbatim Coding
For verbatim coding, we need a machine learning model that contains a set of rules for each code within the codeframe. For a given verbatim, if a rule for a code matches the verbatim, then the code is applied to the verbatim. If the rules are written in a way that humans can understand, then we have a machine learning model that can be understood and if necessary corrected.
The approach we have taken at Ascribe is to create rules using regular expressions. To be precise, we use an extension of regular expressions as explained in this post. A simplistic way to approach this would be to simply create a set of rules that attempt to match the verbatim directly. This can be a reasonable approach, particularly for short format verbatim responses. We can do better than that, however. A far more powerful approach to support this sentiment analysis is to first run the verbatims through natural language processing (NLP). This results in findings consisting of topics, expressions, extracts, and sentiment scores. Each verbatim comment can produce many findings, containing these NLP elements, which we call the facets of the finding. Natural language processing works well across the board for processing sentiment analysis and understanding the text analysis results to build algorithms and different features.
You can read more about NLP in this blog post, but for our purposes we can define the facets of a finding as:
- Verbatim: the original comment itself.
- Topic: what the person is talking about. Typically a noun or noun phrase.
- Expression: what the person is saying about the topic. Often a verb or adverbial phrase.
- Extract: the portion of the verbatim that yielded the topic and expression, with extraneous sections such as punctuation removed.
- Sentiment score: positive or negative if sentiment is expressed, or empty if there is no expression of sentiment.
Rules in the Machine Learning Model
Armed with the NLP findings for a verbatim we can build regular expression rules to match the facets of each NLP finding to build accurate results. A rule has a regular expression for each facet in the text analysis. If the regular expression for a facet is empty it always matches that facet. Each rule must have a regular expression for at least one facet in the text analysis. If there are multiple regular expressions for the facets of a rule, they must all match the NLP finding to produce a positive match in the algorithm.
Let’s look at a specific example. Suppose we have a code in our codeframe:
- Liked advertisement / product description
Two appropriate rules using the Topic and Expression of the NLP findings would be:

The first rule matches a verbatim where the respondent likes the product description, and the second a verbatim where the respondent likes the ad or advertisement. The | character in the second rule means “OR” in a regular expression.
The key point here is that we can look at the rules and aid in understanding exactly why these rules will code a specific verbatim. This is the explainable part of the model. Moreover, we can change the model “by hand”. It may be that in our set of training examples no respondent said that she loved the ad. Still, we might want to match such verbatims to this code. We can simply change the expressions to:
like|love
to match such verbatims. This is the correctable part of the model.
Applying the Machine Learning Model
When we want to use our machine learning model to code a set of uncoded verbatims, the computer performs these steps:

For newly created models you can be sure that it will not code all the verbatims correctly. You will want to check and correct the coding. Having done that, you should explore the model to tune it so that it does not make these mistakes again.
Exploring the Machine Learning Model
The beauty of an explainable machine learning model is that you can understand exactly how the model makes its decisions. Let’s suppose that our model has applied a code incorrectly. This is a False Positive. Assuming we have a reasonable design surface for the model we can look at the verbatim and discover exactly what rule caused it to apply the code incorrectly. Once we know that we can change the rule to help prevent it from making that incorrect decision.
The same is true when the model does not apply a code that it should, a False Negative. In this case we can look at the rules for the code, and at the findings for the verbatim analysis and add a new rule that will match and support the verbatim. Again, a good design surface is needed here. We want to be able to verify that our rule correctly matches the desired verbatim, but we also want to check whether the new rule introduces any False Positives in other verbatims.
Upward Accuracy Spiral
If you are following closely you can see that the model could be constructed without the aid of the computer. A human could create and review all of the rules by hand. We must emphasize that in our approach the model is created by the computer completely automatically.
With a traditional opaque machine learning model, the only tool you have to improve the model is to improve the training set. With the approach we have outlined here that technique remains valid. But in addition, you can understand and correct problems in the model without curating a new training set. How you elect to blend these approaches is up to you, but unless you spend the time to do careful quality checking of the training set manual correction of the model is preferred. This avoids the frumious downward accuracy spiral.
With a new model you should inspect and correct the coding each time the model is used to code a new set of verbatims, then explore the model and tune it to avoid these mistakes. After a few such cycles you may pronounce the model to have acceptable accuracy and forego this correction and tuning cycle.
Mixing in Traditional Machine Learning
The explainable machine learning model we have described has the tremendous advantage of putting us in full control of the model. We can tell exactly why it makes its decisions and correct it when needed. Unfortunately, this comes at a price relative to traditional machine learning.
Traditional machine learning models do not follow a rigid set of rules like those we have described above. They use a probabilistic approach. Given a verbatim to code, a traditional machine learning model can make the pronouncement: “Code 34 should be applied to this verbatim with 93% confidence.” Another way to look at this is that the model says: “based on the training examples I was given my statistical model predicts Code 34 with 93% probability.”
The big advantage to this technique is that this probabilistic approach has a better chance of matching verbatims that are similar to the training examples. In practice, the traditional machine learning approach can increase the number of true positives but will also increase the number of false positives. To incorporate traditional machine learning into our approach we need a way to screen out these false positives.
At Ascribe, we are taking the approach of allowing the user to specify that a traditional model may be used in conjunction with the explainable model. Each of the rules in the explainable model can be optionally marked to use the predictions from the traditional model. Such rules apply codes based on the traditional model but only if the other criteria in the rule are satisfied.
Returning to the code:
- Liked advertisement / product description
We could write a rule that says: “use the traditional machine learning model to predict this code but accept the prediction only if the verbatim contains one of the words “ad”, “advertisement”, or “description”. In this way we gained control over the false positives from the traditional machine learning model. We gain the advantages of the opaque traditional machine learning model but remain in control.
Machine Learning for Verbatim Coding
Using machine learning to decrease manual labor in verbatim coding has been a tantalizing goal for years. The industry has seen several attempts end with marginal labor improvements coupled with decreased accuracy.
Ascribe Coder is today the benchmark for labor savings, providing several semi-automated tools for labor reduction. We believe the techniques described above will provide a breakthrough improvement in coding efficiency at accepted accuracy standards.
A machine learning tool that really delivers on the promise of speed and accuracy has many benefits for the industry. Decreased labor costs is certainly one advantage. Beyond this, project turn-around time can be dramatically reduced. We believe that market researchers will be able to offer the advantages of open-end questions in surveys where cost or speed had precluded them. Empowering the industry to produce quality research faster and cheaper has been our vision at Ascribe for two decades. We look forward to this next advance in using open-end questions for high-quality, cost effective research.
1/30/20
Read more
Text Analytics & AI
Interpreting Survey Results
Interpreting survey data is an important multi-step process requiring significant human, technology, and financial resources. This investment pays off when teams are able to change directions, delight customers, and fix problems based on the information gained from the results.The type of survey or question sets the direction for respondents and for the resulting survey data. Understanding the options and what kind of perspectives they can reveal is critical to accurately interpreting the responses to the questions.
Types of Survey Questions
Before beginning, review the survey’s goal and the type of survey questions selected. This will help when interpreting the results and determining next steps. The following are frequently used survey types, though many more options exist.
The Net Promoter Score (NPS)
NPS is a widely used survey question that provides insights on how happy customers are with a brand. The result is a number on a scale which answers the primary question “How likely are you to recommend [business or brand] to others in your social circle?” Thus the NPS reports how strong a brand’s word-of-mouth message is at a given time.Some NPS questions follow up with an open-ended comments box. This allows customers to explain or identify the factors that influenced their choice. These verbatim NPS comments can help organizations hone in on where their products or services are exceeding expectations and where things may be breaking down.
Post-Purchase Follow-Up
Asking customers about how satisfied they are with the purchasing process and/or with products or services after they make a purchase can be helpful for businesses seeking to improve their customer journey. Questions include how satisfied the customer is with the experience, how happy they are with their purchase, and whether they’ve had any challenges getting the most out of their purchase.This type of survey helps companies prevent customer unhappiness by improving the path to purchase, identifying weaknesses in the product or service that can be addressed, and asking questions to open up a conversation with unhappy customers early. Proactive customer support can transform a customer’s negative experience into a positive one and create a strong advocate in that customer.
Customer Support Contact Follow-Up
When customers contact a support resource, this kind of survey asks whether the customer’s problem has been fixed. It shows the ability of customer support to solve problems and identifies when the problem isn’t user error but inherent issues within the product, service or customer experience. Knowing this answer helps organizations address the right issue at the right time so their customers remain happy even after they purchase and begin using a product or service.
New Products and Features
A product may perform perfectly within the controlled environment of a lab or development area, only to flounder when tested in a real environment. Inviting customer feedback during the planning stages is important because it can save a company significant time and money as they bring a new product, service, or feature to the market. In addition, businesses satisfy their customers better when they develop the updates and features that their customers want. Asking for input from customers allows companies to see which updates are most important and therefore belong higher on the priority list.
Step Two: Organize the Survey Data and Results
After choosing the type of survey, it’s time to deploy it and review the results. Depending on the survey chosen, organizations may receive only numerical data (such as a net promoter score), numerical and comment data, or comment (textual) data only.When data results come in, organizing it first helps facilitate further data analysis. Questions to consider when organizing data include:
- Did the survey target a particular product or customer segment?
- Did the survey go to people making an initial purchase or to repeat customers (who are already at least somewhat loyal to the business)?
- What are the unique characteristics that separate data sets from one another? Tag the feedback based on these criteria in order to compare and contrast the results of multiple surveys.
- What overall themes appear in the survey data? Is there a commonality amongst respondents? Do a majority of the responses focus on a particular feature or customer service issue? A significant number of references to the same topic indicates something that is particularly positive or negative.
- Is the emotion in the verbatim comments positive or negative? This is sentiment analysis of text responses and gives context to numerical rankings. Sentiment analysis results can show where businesses need to focus improvement effort.
Step Three: Analyze and Interpret the Data
Once the data is organized, the next step is to analyze it and look for insights. Until recently, data analysis required manual processing using spreadsheets or similar applications. Not only is manual analysis tedious and time-consuming (taking weeks or months with large data sets), it is also inconsistent.Manual analysis requires human coders to review all of the data. No two people will review information the same way. The same person may assess it differently on any given day as well. Too many factors can change how an individual assess a set of data, from their physical wellbeing (Hungry? Tired? Coming down with a cold?) to their emotional state. This inconsistency makes it challenging to detect trends and significant changes over time (which businesses need in order to determine whether improvement efforts are working).
Text Analysis Tools
Text analysis tools automate many tasks associated with reviewing survey data, including recognizing themes and topics, determining whether a response indicates positive or negative emotion (sentiment), and identifying categories for this information.Today, companies like Ascribe have developed robust and extremely efficient survey analysis tools that automate the process of reviewing text. Ascribe’s software solutions include sentiment analysis of verbatim comments, which offers greater visibility into customer feedback in minutes, not weeks. Advanced text analytics solutions such as Ascribe's CX Inspector with X-Score can deliver high-level topic analysis or dig deep into sentiment using accelerated workflows that deliver actionable insights sooner.CX Inspector can analyze and synthesize data from multiple channels in addition to surveys, such as social media, customer panels, and customer support notes. This creates a multidimensional big picture of an organization’s relationship with its customers, patients, employees, etc. These tools also drill down into the information through topics and categories. For companies with international products and services, Ascribe’s text analysis and sentiment analysis tools can also perform multi-lingual analysis.X-Score is a patented approach to customer measurement that provides a customer satisfaction score derived from people’s authentic, open-ended comments about their experience. X-Score highlights key topics driving satisfaction and dissatisfaction, helping identify the actions needed to improve customer satisfaction quickly and easily. In this way, companies can cut the number of questions asked in half and reduce the size of the data set without compromising on the quality of data they receive.
How Automated Text Analysis Tools Work
Ascribe’s cutting-edge suite of solutions work by combining Natural Language Processing (NLP) and Artificial Intelligence (AI). This powerhouse duo can sift through slang, regional dialects, colloquialisms, and other non-standard writing using machine learning. The software uses machine learning to interpret meaning and recognize the emotions behind the words, all without human intervention.CX Inspector improves data quality by removing gibberish and profanity, and the software also can improve data security by removing personally identifiable information.
What to Do with Survey Results
The reports provided by CX Inspector appear in easy-to-read charts and graphs. Visuals highlight the challenges that respondents face with an organization’s products or services. They also draw attention to high-functioning areas receiving consistently positive feedback. These reports can reveal repeated topics, trends, and questions, eliminating guesswork and allowing companies to resolve specific complaints about a product or service that comes directly from respondents. Positive feedback highlights strengths and helps businesses capitalize on them (and avoid making changes to things customers are happy with).Neutral sentiment can also be an action item, as it identifies customers who are either apathetic or ambivalent about their experiences with a brand. This category of customer may respond well to extra attention, or they may simply not be the ideal customer. Knowing which is true can keep a business from wasting effort on customers they cannot please and help them stay focused on the customers they can.People like to feel heard and to know that their opinions are valued by the companies and brands they do business with. Surveys and reviews give them the opportunity to give feedback. But surveys by themselves do not satisfy customers, patients, and employees. The highest value of these surveys comes from interpreting the data correctly, learning from it, and using it to improve experiences, loyalty, and retention.
9/25/19
Read more
Text Analytics & AI
Using Sentiment Analysis to Improve Your Organization’s Satisfaction Score
Whether it’s a rating, ranking, score, review, or number of stars/tomatoes/thumbs up, consumers have ample opportunities to report their experiences with businesses, service providers, and organizations in the form of survey responses and other user-generated content. The challenge for organizations remains processing this high volume of data, finding positive and negative sentiment, identifying opportunities for improvement, and tracking the success of improvement efforts.
What Sentiment Scores Can’t Tell You
Numbers without context cannot inform real improvements. If an organization receives a sentiment score of 72, the leadership team may recognize that the score is good or bad but have no information about what is influencing it either way. Worse still, a simple number does not reveal what to do to raise it.A rational approach to improving is to look at a sentiment score and ask, “What is contributing to that number? What’s keeping us from earning a higher one?”Analyzing the user-generated content and text-based survey results that accompany numbers, scores, and ratings provides that context and helps guide efforts towards the most significant changes to make. However, manual analysis of text is extremely time-consuming and nearly impossible to do consistently. Without a systematic and efficient process in place, organizations will remain largely in the dark about how to improve their constituents’ experiences.When Ascribe launched automated text analytics programsCX Snapshot and CX Inspector with X-Score™, they decreased the time it takes to review comments from weeks to hours. These programs perform text sentiment analysis using natural language processing (NLP) and report findings using visuals (charts and diagrams) to highlight trends, trouble spots, and strengths.X-Score is a patented approach to customer measurement that provides a customer satisfaction score derived from people’s authentic, open-ended comments about their experience. X-Score highlights key topics driving satisfaction and dissatisfaction, helping identify the actions needed to improve customer satisfaction quickly and easily. In this way, companies can cut the number of questions asked in half and reduce the size of the data set without compromising on the quality of data they receive.
Consumer Glass Company Gains Sentiment Data within Hours with Automated Text Analysis
A major consumer glass company serves more than 4 million customers each year across the United States. They received 500,000 survey responses, which produced massive data sets to review. They needed to interpret the verbatim comments and connect them with other data, like Net Promoter Scores® (NPS). This would enable them to understand exactly how to delight every customer every time.The company tried a standard text analytics software, but its results were inconsistent. The system took days or weeks to model the data and could not connect the sentiment analysis with their NPS data.Within a week of obtaining Ascribe’s natural language processing tool CX Inspector with X-Score, the software was delivering exactly the kind of analysis needed. CX Inspector now reviews customer feedback comments from surveys, social media, and call center transcriptions, and the company has a strategic way to use the data and trust it to inform sound business decisions. Their customer and quality analytics manager says,
“NPS is a score, and you don’t know what’s driving that score. But when you can see how it aligns with sentiment, then that informs you as to what might be moving that NPS needle. In every instance where I compared CX Inspector output with NPS, it was spot-on directionally, so it gives us a lot of confidence in it – and that also helps to validate the NPS.
“Without a text analytical method like CX Inspector, it is extremely difficult to analyze this amount of data. Ascribe provides a way to apply a consistent approach. This really allows us to add a customer listening perspective to our decision making.”
How Sentiment Analysis Informs Your Organization’s Improvement Efforts
Reviewing the verbatim comments of individuals who have experienced a product or service provides essential data for teams looking for trouble spots, trends, and successes. This analysis of text reveals specific areas of service that are suffering even if other areas are doing well.For example, text sentiment analysis can find consistently satisfied customers in nine of the interactions they have with an organization, and also highlight that tenth interaction that’s consistently unsatisfactory.Having this detail empowers organizations to focus their efforts on the handful of areas contributing most to the unhappiness of the people involved (whether they’re employees, customers, patients, etc.). By implementing change and then checking current against previous scores and sentiment, organizations can also measure their progress.
Regional Bank Experiences 60% Decrease in Processing Time
Recently a regional bank approached Ascribe in search of a more efficient and effective tool for finding positive and negative sentiment from customer feedback and analyzing it for specific changes that would enhance their customers’ experiences. They had been consuming thousands of man-hours reading, categorizing, and analyzing comments. Yet they still struggled to identify the most important themes and sentiment, and the manual process was inconsistent and unable to show trends over time.In minutes, Ascribe’s CX Snapshot processed a year’s worth of customer feedback gathered from all channels. It identified trends the team had been unable to unlock using their manual processes, and it quickly identified steps to take to improve the customer experience. The repeatable methodology ensured consistent analysis from month to month, making it possible to track trends over time.A senior data scientist on the bank’s staff says,
“This new approach is repeatable, powerful, and it expedites our ability to act on the voice of the customer.”
How Asking Better Questions Improves Insights
Another way to improve the efficiency and effectiveness of surveys is to ask questions in a better way, which reduces the number of questions needed. This works because it captures better data, as the consumer is not being forced to respond to leading questions. For example, asking, “What did you not like?” could lead consumers to provide a negative answer even though their overall experience was very positive. "Tell us about your experience" is more neutral and allows for consumers to give either a positive or negative response.Asking fewer and better questions also reduces interview fatigue, thereby increasing the number of completed surveys and improving the survey-taking experience. It recognizes that people who choose to fill out a questionnaire usually have something very specific to share. Rather than making people work to fit their comments into question responses, "Tell us about your experience" invites consumers to immediately provide their feedback.Ascribe’s text analytics tools help researchers in both of these areas. Often, all the feedback needed can come from this single open-ended question: “Tell us how we’re doing.”
Recommendations
Sentiment analysis tools are an essential component of an organization’s improvement efforts. A robust and strategic approach will automate surveying and the processing of user-generated content like reviews, social media posts, and other verbatim comments. Using machine learning, natural language processing, and systems that visualize the positive and negative themes that emerge can empower organizations to make decisions based on data-driven insights. Today, this kind of automated analysis can review massive data sets within hours and inform organizations of the specific steps to take to improve the satisfaction of their constituents. Ascribe’s suite of software solutions does just this, simplifying and shortening analysis time so organizations can focus on what needs to be improved, and then see better results faster.
9/16/19
Read more
.jpeg)
Text Analytics & AI
Verbatim Analysis Software - Easily Analyze Open-Ended Questions
Do you want to stay close to your customers? Of course you do!
Improving the customer experience is central to any business. More broadly, any organization needs to stay in touch with its constituents, be they customers, employees, clients, or voters.
In today’s world, getting your hands on the voice of the customer isn’t difficult. Most companies have more comments from their customers than they know what to do with. These can come from internal sources, such as
- E-mails to your support desk.
- Transcriptions from your call center.
- Messages to your customer service staff.
- Notes in your CRM system.
- Comments from website visitors.
For most companies, the problem isn’t lack of feedback. It’s the sheer volume of it. You might have thousands or even hundreds of thousands of new comments from your customers.
The question is, “How do you make sense of it?”
Traditional Survey Research
Traditional survey market research gives us some clues. Market research firms have been using surveys for years to guide their clients to improve customer satisfaction.
They have developed very powerful techniques to analyze comments from customers and turn them into actionable insights. Let’s take a look at how they do it to see whether we can come up with some ways to take our voice of the customer data and find new insights to improve your company.
How Survey Market Researchers Use Verbatim Analysis Software To Deal With Open-Ends
A survey has two fundamental question types: closed-end and open-end. A closed-end question is one where you know the possible set of answers in advance, such as your gender or the state you live in.
When a respondent provides a free form text response to a question it is an open-end: you don’t know just what the respondent is going to say. That’s the beauty of open-ends. They let our customers tell us new things you didn’t know to ask.
Survey researchers call the open-end responses verbatims or text responses. To analyze the responses the researcher has them coded. Humans trained in verbatim coding read the responses and invent a set of tags or codes that capture the important concepts from the verbatims.
In a survey about a new juice beverage the codes might look something like:
- Likes
- Likes flavor
- Likes color
- Likes package
- Dislikes
- Too sweet
- Bad color
- Hard to open
Human coders read each verbatim and tag it with the appropriate codes. When verbatim coding is completed, we can use the data to pose questions like
- What percentage of the respondents like the flavor?
- What is the proportion of overall likes to dislikes?
And if you know other things about the respondents, such as their gender, you can ask
- Do a greater percentage of men or women like the flavor?
The researcher would say that you have turned the qualitative information (verbatims) into quantitative information (codes).
How Can Verbatim Coding Work for You?
The technique of verbatim coding is used to analyze comments from customers, but it has its drawbacks. Verbatim coding is expensive and time consuming. It’s most appropriate when you have high quality data and want the best possible analysis accuracy.
In that circumstance, you can either:
- Have the verbatims coded by a company specializing in the technique, or
- License software so that you can code the verbatims yourself.
Verbatim analysis software, like Ascribe Coder, is used by leading market research companies around the globe to code verbatims. This type of software increases productivity dramatically when compared to using more manual approaches to coding – like working in Excel.
Returning attention to our pile of customer comments, we can see that it would be great to get the benefits of verbatim coding without the cost. It would be great to leverage the computer to limit the cost and timing, with less involvement from human coders.
That’s where text analytics comes in.
Using Text Analytics To Analyze Open Ends
Working with customer comments, text analytics can tell us several things
- What are my customers talking about? (These are topics.)
- What customer feedback am I getting about each topic? (These are expressions about topics.)
- How do they feel about these things? (These are sentiment ratings.)
If you were running a gym, you might get this comment:
- I really like the workout equipment, but the showers are dirty.
Text analysis identifies the topics, expressions and sentiment in the comment:
If we run a few thousand comments about our gym through text analytics, we might get results like this:
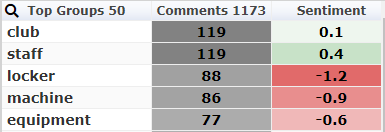
These are the things your members are talking about most frequently.
Each topic has an associated frequency (the number of times the topic came up) and a sentiment rating.
The sentiment rating for this analysis ranges from -2 as strong negative to +2 as strong positive. The sentiment scores are the averages for each topic.
Data Analysis: Drilling Into the Data
A good text analytics tool presents much more information than the simple table above. It will let you drill into the data, so you can see exactly what your customers are saying about the topics.
It should also let you use other information about your customers. For example, if you know the gender of each member, you can look at how the women’s opinions of the showers differ from the men’s.
Text Analytics Uncovers Important Insights For Your Business
With your text analytics solution, you can see immediately that your guests are generally positive about the staff. But you seem to have a problem with the lockers and the equipment. This lets you resolve the problem quickly – before any other customers have a bad experience.
Find Out Whether Verbatim Analysis Software Or Text Analytics Is Right For Your Business
Verbatim coding is a very well-developed part of traditional survey research. The coders who lead the analysis are experts in verbatim coding and the verbatim analysis software and play an important role in overseeing the analysis and the results. Verbatim coding produces very high accuracy, but it can also be expensive and time consuming. Text analytics also analyzes open ends, relying more on the computer to analyze the open end comments to uncover insights. While results are not quite as accurate, it does so at a fraction of the time and cost.Ascribe provides both traditional verbatim coding with Coder and advanced text analytics with CX Inspector. To learn more about whether Verbatim Coding or Text Analytics is right for your business, contact us or schedule a demo today.
7/23/19
Read more
Text Analytics & AI
Ascribe Regular Expressions
Ascribe allows the use of regular expressions in many areas, including codes in a codebook and for various search operations. The regular expressions in Ascribe include powerful features not found in standard regular expressions. In this article we will explain regular expressions and the extensions available in Ascribe.
Regular Expressions
A regular expression is a pattern used to match text. Regular expressions patterns are themselves text, but with certain special features that give flexibility in text matching.In most cases, a character in a regular expression simply matches that same character in the text being searched.The regular expressionlovematches the same four characters in the sentence:I loved the food and service.We will write:love ⇒ I loved the food and service.To mean “the regular expression ‘love’ matches the underlined characters in this text”.Here are a few other examples:e ⇒ I loved the food and service.d a ⇒ I loved the food and service.b ⇒ Big Bad John.Note in the last example that in Ascribe regular expressions are case insensitive. The character ‘b’ matches ‘b’ or ‘B’, and the character ‘B’ also matches ‘b’ and ‘B’.So far regular expressions don’t seem to do anything beyond plain text matching. But not all characters in a regular expression simply match themselves. Some characters are special. We will run through some of the special characters you will use most often.
The . (dot or period) character
A dot matches any character:e. ⇒ I loved the food and service.To be precise, the dot matches any character except a newline character, but that will rarely matter to you in practice.
The ? (question mark) character
A question mark following a normal character means that character is optional. The pattern will match whether the character before the question mark is in the text or not.dogs? ⇒ A dog is a great pet. I love dogs!
Character classes
You can make a pattern to match any of a set of characters using character classes. You put the characters to match in square brackets:cott[oeu]n ⇒ Cotton shirts, cotten pants, cottun blouseBoth the question mark and character classes are great when trying to match common spelling errors. They can be particularly useful when creating regular expressions to match brand mentions:budw[ei][ei]?ser ⇒ Budweiser, Budwieser, Budwiser, BudweserNote that the question mark following a character class means that the character class is optional.Some character classes are used so often that there are shorthand notations for them. These begin with a backslash character.The \w character class matches any word character, meaning the letters of the alphabet, digits, and the _ (underscore) character. It does not match hyphens, apostrophes, or other punctuation characters:t\we ⇒ The tee time is 2:00.The backslash character can also be used to change a special character such as ? into a normal character to match:dogs\? ⇒ A dog is a great pet. Do you have any dogs? I love dogs!
Quantifiers
The quantifiers * and + mean that the preceding expression can repeat. The * means the expression can repeat zero or more times, and the + means the preceding expression can repeat one or more times. So * means the preceding expression is optional, but if present it can repeat any number of times. While occasionally useful following a normal character, quantifiers are more often used following character classes. To match a whole word, we can write:\w+ ⇒ I don’t have a cat.Note that the apostrophe is not matched.
Anchors
Anchors don’t match any characters in the text, but match special locations in the text. The most important of these for use with Ascribe is \b, which matches a word boundary. This is useful for searching for whole words.\bday\b ⇒ Today is the Winter solstice. Each day gets longer, with more hours of daylight.Combined with \w* we can find words that start with “day”:\bday\w*\b ⇒ Today is the Winter solstice. Each day gets longer, with more hours of daylight.or words that contain “day”:\b\w*day\w*\b ⇒ Today is the Winter solstice. Each day gets longer, with more hours of daylight.Two other useful anchors are ^ and $, which match the start and end of the text respectively.
Alternation
The vertical bar character | matches the expressions on either side of it. You can think of this as an OR operation. Here is a pattern to match either the word “staff” or one starting with “perso”:\bstaff\b|\bperso\w+\b ⇒ The staff was friendly. Your support personnel are great!
Regular expression reference
This is just a glimpse into the subject of regular expressions. There are books written on the subject, but to make effective use of regular expressions in Ascribe you don’t need to dig that deep. You can find lots of information about regular expressions on the web. Here is one nice tutorial site:RegexOneThe definitive reference for the regular expressions supported in Ascribe is found here:Regular Expression LanguageYou can also download a quick reference file:Regular Expression Language - Quick Reference
Ascribe Extended Regular Expressions
Ascribe adds a few additional operators to standard regular expressions. These are used to tidy up searching for whole words, and to add more powerful logical operations.
Word matching
As we have mentioned, you can use \b to find whole words:\bstaff\b|\bperso\w+\b ⇒ The staff was friendly. Your support personnel are great!But those \b’s and \w's make things hard to read. Ascribe allows you to use these notations instead:NotationStandard regex equivalentMeaning<(\bStart of word>\b)End of word<<(\b\w*Word containing ...>>\w*\b)... to end of wordWe can now write:<as> (the word “as”)<as>> (a word starting with “as”)<<as> (a word ending with “as”)<<as>> (a word containing “as”)Examples:<staff>|<perso>> ⇒ The staff was friendly. Your support personnel are great!<bud> ⇒ Bud, Bud light, Budweiser, Budwieser<bud>> ⇒ Bud, Bud light, Budweiser, Budwieser<<ser> ⇒ Bud, Bud light, Budweiser, Budwieser<<w[ei]>> ⇒ Bud, Bud light, Budweiser, BudwieserIf you look in the table above, you will note that each of the standard regular expression equivalents have a parenthesis in them. Yes, you can use parentheses in regular expressions, much as in algebraic formulas. It’s an error in the regular expression to have a mismatched parenthesis. So, the pattern:<asis not legal. The implied starting parenthesis has no matching closing parenthesis. This forces you to use these notations in pairs, which is the intended usage.The use of these angle brackets does not add any power to regular expressions, they just make it easier to read your expressions. The logical operators I describe next do add significant new power.
Logical operators
We have seen that it is easy to search for one word or another:<staff>|<personnel>matches either of these words. What if we want to search for text that contains both the words “cancel” and “subscription”? This is not supported in standard regular expressions, but it is supported in Ascribe. We can write<cancel>&&<subscription>This matches text that contains both words, in either order. You can read && as “AND”.We can also search for text that contains one word and does not contain another word. This expression:<bud>>&~<light>|<lite>matches text that contains a word starting with “bud” but does not contain “lite” or “light”. You can read &~ as “AND NOT”.The && and &~ operators must be surrounded on either side by valid regular expressions, except that the &~ operator may begin the pattern. We can rewrite the last example as:&~<light>|<lite>&&<bud>>which means exactly the same thing.Pay attention to the fact that these logical operators require that the expressions on either side are valid on their own. This pattern is illegal:(<cancel>&&<subscription>)because neither of the expressions(<cancel><subscription>)are legal when considered independently. There are mismatched parentheses in each.
Pattern prefixes
There are two prefixes you can use that change the meaning of the match pattern that follows them. These must be the first character of the pattern. The prefixes are:*Plain text matching>Standard regular expression matching, without the Ascribe extensionsThese prefixes are useful when you are trying to match one of the special characters in regular expressions. Suppose we really want to match “why?”. Without using a prefix gives:why? ⇒ What are you doing and why? Or why not?But with the * prefix we can match the intended word only (with the question mark):*why? ⇒ What are you doing and why? Or why not?The > prefix is useful if you are searching for an angle bracket or one of the Ascribe logical operators:>\d+ < \d+ ⇒ The algebraic equation 22 < 25 is true.It helps to know that \d matches any digit.
Summary
Regular expressions are a powerful feature of Ascribe. Spending a little time getting used to them will pay off as you use Ascribe. The Ascribe extensions to regular expressions make searching for words easier, and support logical AND and NOT operations.
3/18/19
Read more